Cache高速缓存和缓存隔离
Updated:
Cache的历史
在科研领域,C. J. Conti等人于1968年在描述360/85和360/91系统性能差异时最早引入了高速缓存(cache)一词。Alan Jay Smith于1982年的一篇论文中引入了空间局部性和时间局部性的概念。
Mark Hill在1987年发明了3C(Compulsory, Capacity, Conflict)冲突分类。
最早介绍非阻塞缓存的论文之一来自David Kroft(1981年)。
1990年Norman Paul Jouppi在一篇论文中介绍了受害者缓存并研究了使用流缓冲器进行预取的性能。
在工业领域,最早的有记载的缓存出现在IBM的360/85系统上。
Intel的x86架构CPU从386开始引入使用SRAM技术的主板缓存,大小从16KB到64KB不等。486引入两级缓存。其中8KBL1缓存和CPU同片,而L2缓存仍然位于主板上,大小可达268KB。将二级缓存置于主板上在此后十余年间一直设计主流。但是由于SDRAM技术的引入,以及CPU主频和主板总线频率的差异不断拉大,主板缓存在速度上的对内存优势不断缩水。因此,从Pentium Pro起,二级缓存开始和处理器一起封装,频率亦与CPU相同(称为全速二级缓存)或为CPU主频的一半(称为半速二级缓存)。
AMD则从K6-III开始引入三级缓存。基于Socket 7接口的K6-III拥有64KB和256KB的同片封装两级缓存,以及可达2MB的三级主板缓存。
今天的CPU将三级缓存全部集成到CPU芯片上。
多核CPU通常为每个核配有独享的一级和二级缓存,以及各核之间共享的三级缓存。
什么是Cache?
在wikipedia上对cache的解释:
In computing, a cache is a hardware or software component that stores data so future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation, or the duplicate of data stored elsewhere. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests can be served from the cache, the faster the system performs.
字面上理解就是,cache是一个硬件或软件的组件用来存储将来会请求到的数据,而且能让数据获取更快。因为如今缓存的概念已被扩充,不仅在CPU和主内存之间有Cache,而且在内存和硬盘之间也有Cache(磁盘缓存),乃至在硬盘与网络之间也有某种意义上的Cache──称为Internet临时文件夹或网络内容缓存等。凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为Cache。
- 硬件的cache:CPU cache,GPU cache,DSP;
- 软件的cache:Disk Cache,Web Cache等。
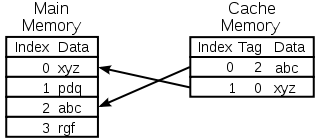
这里我们着重讨论传统的cache缓存:CPU的cache。不同的存储技术有着不同的价格和性能的折中。不同存储器访问时间差异很大,速度较快的技术每字节的成本要比速度较慢的技术高,而且容量小。金字塔存储器层次结构如下图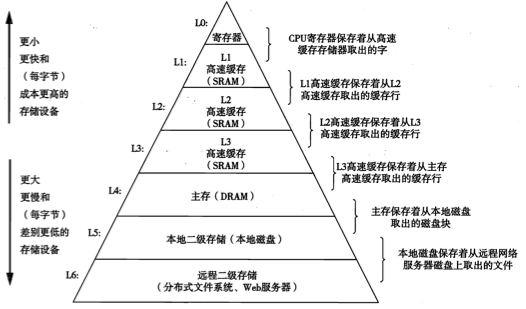
一般而言,高速缓存(cache)是一个小而快的存储设备,它作为存储在更大也更慢的设备中的数据对象的缓冲区域。使用高速缓存的过程成为缓存(caching)。cache的效率由命中率来衡量,一个好的cache效率通常在80%-95%的命中率。
缓存命中
在存储器层次结构中,假设层次从上到下是增序排列,假设一个k值,当程序需要第k+1层的某个数据对象d时,它首先在第k层的一块中查找d,如果d刚好缓存在k层中,就是缓存命中(cache hit).
缓存不命中
当在k层找不到数据d时,我们就称k层缓存不命中(cache miss)。当发生缓存不命中的时候,第k层缓存从第k+1层缓存中取出包含d的那个块,如果k层缓存满了,就会覆盖现有的块。
覆盖一个现存的块的过程称为替换(replacing)或驱逐(evicting)这个块。被驱逐的块称为牺牲(victim)块。关于替换哪个具体的块是由替换策略来控制的。比如随机替换策略,或最少最近被使用策略(LRU)。
缓存不命中的种类
- 强制不命中或冷不命中:这种不命中是由于缓存是空的,它通常是短暂的,不会在反复访问存储器的过程中出现。
- 冲突不命中:这种缓存是由于放置策略引起的。如下图所示,如果程序请求0,然后8,然后0,然后8,就会出现每次都不命中
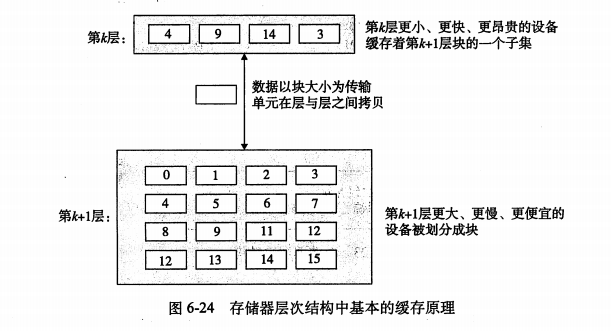
图3 - 容量不命中:当工作集的大小超过了缓存的大小的时候,不能处理这个工作集,就会发生容量不命中。
高速缓存存储器(SRAM)层级
- L1(一级缓存):一般与处理器同片封装,访问速度几乎和寄存器一样快,通常是2-4个时钟周期,大小为8KB-128KB
- L2(二级缓存):可以在chip中也可以在外部,访问速度大约是是10个时钟周期,大小为64KB-8MB
- L3(三级缓存):在chip外部被多核处理器共享,访问速度大约是30~40个时钟周期,大小为4MB-128MB
- L4(四级缓存):cc-NUMA集群系统的远程cache,大小比L3缓存大(大于512MB).
高速缓存结构
一般而言,高速缓存的结构可以用元组(S, E, B, m)来表示,缓存大小C=B×E×S。如下图所示,每个存储器有m位,一个机器的高速缓存是一个有S个高速缓存组(cache set)的数组,每个组包含E行高速缓存行(cache line),每个行由一个B字节的数据块,一个有效位(valid bit)表示这个行是否有有意义的信息,t个(t=m-(b+s))标志位(用于标识存储在这个高速缓存块中的位置)组成。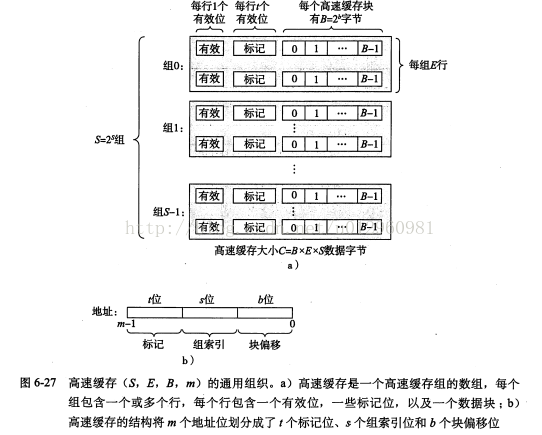
高速缓存确定一个请求是否命中,然后取出被请求的字的过程分为3步:
- 组选择
- 行匹配
- 字抽取
人们根据E(每个组的行数)的不同把高速缓存分成不同类,主要有
1. 直接映射高速缓存(Direct Mapped cache)
每个组只有一行的高速缓存为直接映射高速缓存。
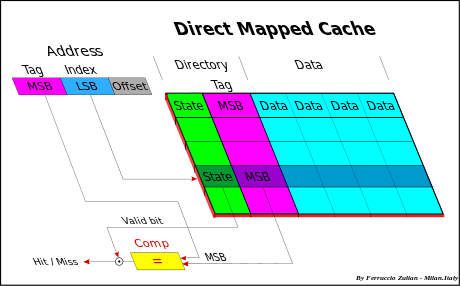
直接映射缓存的操作:
1)组选择:根据s位组索引位选择出组;2)行匹配:确定是否有字w的拷贝存储在组的高速缓存行中,当设置了有效位,并且行中的标记与w的地址中的标记相匹配的时候,我们认为这一行包含w的一个拷贝。因为每个组只有一行,所以很快就可以完成。如果找到了就是命中,反之不命中。 3)如果不命中要进行行替换 4)取出数据块
2. 组相联高速缓存(Set Associative cache)
我们知道,直接映射高速缓存会造成冲突不命中,原因是每个组织有一行。那么组相联高速缓存则是1
3. 全相联高速缓存(Fully Associative cache)
全相联高速缓存的条件是E=C/B,也就是缓存只有一组,组中包含E行。这样的相联完全免去了索引的使用
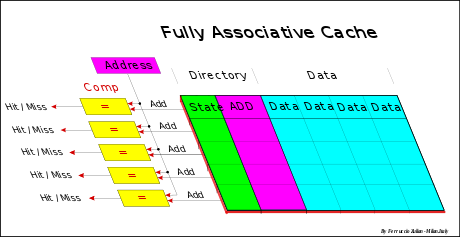
策略
在缓存的读写操作中,有不同的策略来指导操作的顺序以及位置。
替换策略
上文提到,覆盖一个现存的块的时候会使用替换策略,替换策略有很多种,主要有:
- LRU - Least Recently Used
通常用于组相联高速缓存,会有一个age counter(替换index)与每个数组S相关。这个counter最大值就是S,当一个set被访问到,那么比它低的counter就被置为0,其他set自增1。举个例子,有4个set的缓存,原本的counter值是0-3-2-1,如果第三个被访问到了,那么counter的值是1-3-0-2。 - FIFO - First-In First-Out
先进先出策略,通常用于组相联高速缓存。 - LFU – Least Frequently Used
很高效的算法,但很耗资源,通常不用。 - Round-robin
用于全相联高速缓存。有一个指针指向将要被替换的行,当行被替换,指针就会自增1,指针是环形的。 - Random
随机策略,用于全相联高速缓存。每个时序Round-robin就要更新,而不是每个替换操作。
回写策略
cache的回写策略决定怎么把cache的数据写到内存的位置中去。有两种基本的策略:
- 写回(write back)
写回是指,仅当一个缓存块需要被替换回内存时,才将其内容写入内存。如果缓存命中,则总是不用更新内存。为了减少内存写操作,缓存块通常还设有一个脏位(dirty bit),用以标识该块在被载入之后是否发生过更新。如果一个缓存块在被置换回内存之前从未被写入过,则可以免去回写操作。写回的优点是节省了大量的写操作。这主要是因为,对一个数据块内不同单元的更新仅需一次写操作即可完成。这种内存带宽上的节省进一步降低了能耗,因此颇适用于嵌入式系统。 - 写通(write through)
写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个缓存块大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
写通较写回易于实现,并且能更简单地维持数据一致性。
如何编写高速缓存友好的代码
当明白了高速缓存的原理后,我们在编程的过程中应该试着去编写高速缓存友好的代码。什么样的代码算是高速缓存友好的代码?局部性比较好的程序往往有更高的缓存命中率,而缓存命中率更高,代码运行的速度就更快。确保代码高速缓存友好的方法有:
- 让最常见的情况运行得快。
程序通常大部分时间都在少量的核心函数上,而核心函数大部分时间都花在循环上面,让这些循环执行得快一点是我们需要关注的地方。 - 在每个循环内部缓存不命中率数量小。
举个经典的二维数据相加求和的例子:12345678int colsarray(int a[M][N]){int i,j,sum=0;for(i = 0; i<N; i++)for(j = 0; j<M; j++)sum += a[i][j];return sum;}
这个程序中内循环遍历行,外循环遍历列,一列一列地扫描过来,而由于缓存从内存中抓取的几乎都是同行不同列的数据,在接下来的循环中几乎没法被重负利用。如果只是做个小改动,把内外循环交换一下
这样如果a[i][0]失效,从内存中抓取的数据实际上包括了a[i][0]-a[i][7](假定使用32字节大小的缓存块,每个整型值占四字节),这样后面7次循环缓存都可以命中。大大提高了缓存命中率。在实际的运行过程中,第二种的程序比第一种快2倍。
缓存隔离方法
同一台服务器上的CPU数量在近几年一直在增加,32核->48核->72核,为了提高资源使用率,同一台机器上会同时运行很多应用,在同一个物理CPU的不同逻辑CPU上或者某个CPU package上不同物理CPU运行的应用会共享LLC(Last level cache),这样一个batch应用如果需要大量的读写LLC,会占据大部分LLC,导致LS(Latency Sensitive)应用在读取数据时产生cache miss,对于LS应用来说,batch应用会是一个noisy neighbor。
缓存隔离技术哪家强,Intel在CPU微架构Haswell开始引入RDT(Resource Director Technology)技术,其中有一个功能是Cache Allocation Technology (CAT),可以通过设置给不同的core分配不同的cache way,做到cache资源隔离。可以认为CAT使得LLC变成了一种支持QoS(Quality of Service)的资源,操作系统或者容器软件可以限制应用只能使用为其划分的部分cache区域,为不同应用划分的cache区域可以重叠。该功能在分配cache line时起作用,比如读取数据到cache的时候。不同的cache区域是通过CLOS(Class of Service)标记来区分的,每个CLOS有一个CBM(Cache Bit Mask)。CBM是一个连续的bits,定义了每个cache区域可用的cache大小。
CAT可以在cloud和container环境下,更好的分配管理具有大LLC的高性能服务器。比如具有72个core的服务器上,需要同时运行web服务器,数据库和Map Reduce任务等。可以通过cache的分区隔离,使不同应用同时达到更好的资源共享效果。
因为CAT支持在应用运行时动态修改cache的分区,可以配合上层监控系统更好的优化LS的性能同时最小化对batch应用的影响。
一个典型的例子就是解决之前提到的noisy neighbor。在container环境下,一个运行在container里面的streaming应用不停的读写数据导致大量的LLC占用,会导致同机器上另外一个container里运行的LS需要的数据被evict出LLC,从而导致LS应用性能下降。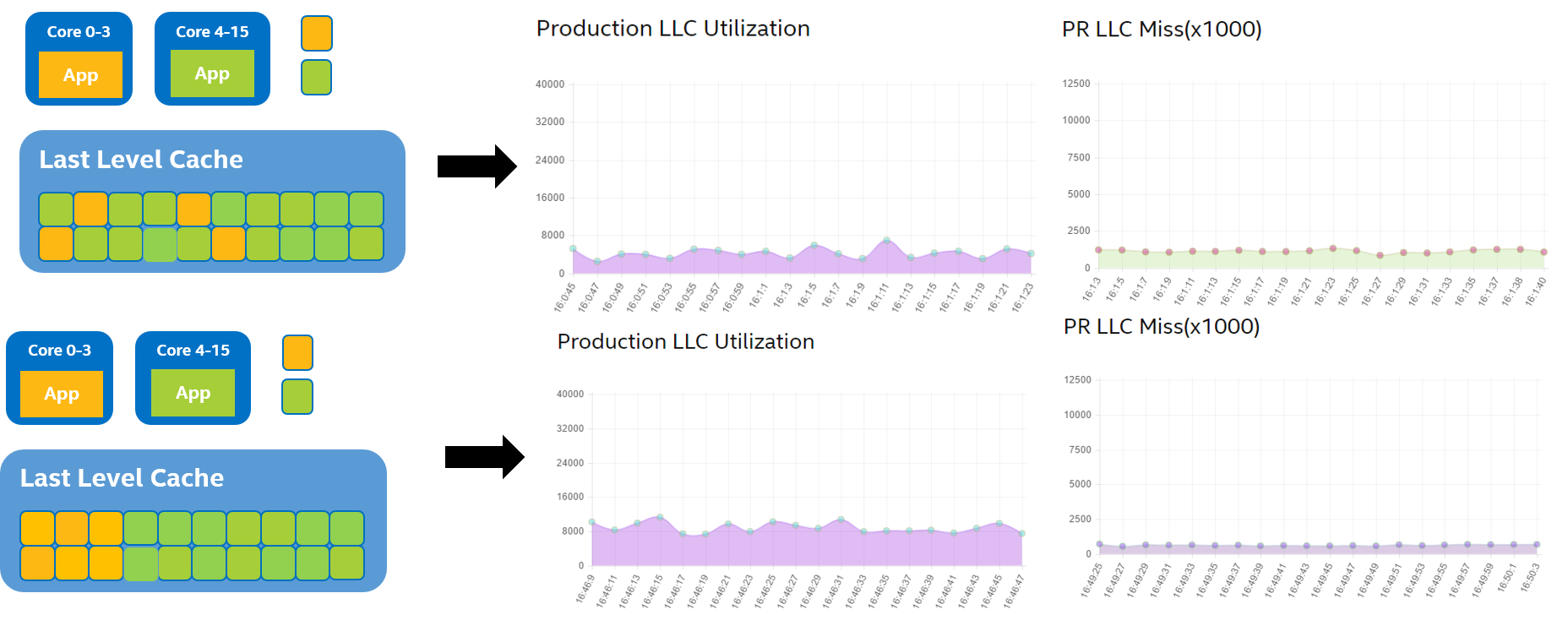
更多关于CAT相关的硬件实现细节,请查阅Intel Software Developer Manual的第17.17节。